

I'm delighted with my new photo sorting tool, which I developed to help me organise over 20,000 photos from the last six or so years.
Today, I sorted just over 900 photos and videos in just over an hour. This would have taken a lot longer in the past and required a bit more thinking with the drag-and-drop process of moving files and previewing each image or video. Although this only runs on my MacBook and is pretty fixed to a folder, I've written it so that it could indeed be changed.
It's also been a really easy application to write and only requires a few lines of code, all of which are embedded into one PHP file. It does require a web server to run and knowledge of how to use symb links.
Once I'm done with it, I'll post the source code to my GitHub.
After losing (or potentially being picked up by someone) my previous AirPods (first-generation Pros, bought in 2020), I constantly debated between purchasing new ones or attempting to find my existing ones. AirPods serve one purpose: to listen to audio.
It's simply not exciting to buy new AirPods like it is with a new MacBook or, on occasion, an iPhone. That meant there seemed to be more value in finding my old AirPods over buying new ones and dropping £250 on something that does mostly the same as the previous ones. That said, I've been using other earphones for the time being, and the difference between them and the AirPods they are covering for is phenomenal. I have seriously missed them.
Almost two months have passed since I first noticed I couldn't find them, and I must admit, it's been not easy without them. Going on runs or walks without them and using poor-quality earphones has been awful. Switching between my MacBook and my iPhone or Apple Watch has been a bit of a nightmare, but worst of all, I cannot watch films in my bedroom late at night with my windows open because my wireless earphones will not connect to my TV as my AirPods do. These are just small things, and I do get it, but I never like perpetually looking for something, and at some point, you do need to declare enough is enough and buy replacement ones - they just weren't going to show up.
So I did just that. I took my advice and opted to drop £230 on new ones to replace something that may eventually turn up.
How these change my technological lifestyle
These AirPods have resulted in a significant milestone in my technological life. The 2nd generation AirPods Pro now features USB-C charging, a game changer for me. One of my childhood 'dreams', I guess, was that one day, we would have one connector for everything. USB attempted this, but it didn't quite do it as it didn't support everything (such as video streams over the connector), so it wasn't really the right connector for everything. That's where USB-C changed everything, as I said back in 2015 when discussing Thunderbolt 3.
Now, my AirPods mean I no longer need a Lightning cable in my backpack. USB-C charges everything, and while I use my MagSafe connector with my MacBook Pro more than any other, at least my MacBook Pro can be charged with USB-C if that was all I had.
Finally, one connector that does it all.

Last night was one of the most significant landslide victories ever achieved by a party in the UK's history. Although not as substantial as Blair's or Thatcher's victories, the fact that the Conservative party has dropped so low is awe-inspiring.
Below is an interactive graph showing the number of seats gained graphically:
And here is another one showing the share of the vote achieved by each party, and it's not quite as red as the previous graph:
I'm most impressed by Ed Davey, who has drawn me back to the Liberal Democrats again.
Strangely, this is the first time I've had a new UK government since I started to vote 14 years ago.
This is an exciting time in politics personally as this represents the first change in a long time. Keir Starmer seems like an honest guy (he'd have to be to have worked in law beforehand), and I feel he's the right person to do the job. The Lib Dems have recovered very well from this election, too, and I'm not surprised with Ed at the helm.
Starmer seems to care for all four parts of the country too:
We clearly on Thursday got a mandate from all four nations. For the first time in 20 plus years we have a majority in England, in Scotland and in Wales and that is a clear mandate to govern for all four corners of the United Kingdom and therefore I shall set off tomorrow to be in all four nations.
I usually come up with codenames for the next version of ZPE quite far in advance, and this year is no exception.
For version 1.13, the following codenames have been decided:
- Petergate
- Micklegate
- Davygate
- Castlegate
- Monkgate
- Goodramgate
- Fossgate
- Colliergate
- Gillygate
- Walmgate
- Coppergate
- Stonegate
Additionally, ZPE 1.14 will also continue this naming strategy with:
- Merchantgate
- Hungate
- St Saviourgate
- St Andrewgate
- Bishopgate
- Swinegate
- Spurriergate
- Ousegate
- Skeldergate
- Fishergate
- Nessgate
- Deangate
The inspiration for these codenames came from the City of York, where I recently had a short break.
ZPE 1.12.7 is now available to download. This version brings sweeping changes to the way that libraries are imported into YASS code and the ZRE; it introduces bubbling, brings breakpoints to ZPE, fixes an issue with permission levels not being read correctly, and, perhaps most importantly, adds unescaped string literals to the YASS language.
All of these features makes ZPE 1.12.7 one of the most jam-packed releases of ZPE to date.
Here is a program for a linear search I wrote in YASS some few months ago.
function linearSearch($item_list, $search_item) : number | boolean { $found = false $index = 0 $position = -1 while ($index < count($item_list) and $found == false){ if ($item_list[$index] == $search_item){ $found = true $position = $index } $index++ } if($found){ print("Item found at position", $position) } else{ print("Item not found") } } function main(){ $l = [3, 5, 7] linearSearch($l, 6) }
And here it is converted to Python using ZenPy:
def linearSearch(item_list, search_item): found = False index = 0 position = -1 while index < len(item_list) and found == False: if item_list[index] == search_item: found = True position = index index += 1 if found: print("Item found at position", position) else: print("Item not found") def main(): l = [3, 5, 7] linearSearch(l, 5) main()
I have been seeking to add breakpoints to ZPE for the last seven years, and I have finally succeeded.
They work using the new bubbling technique I have developed. In ZPE, bubbles are exceptions; a breakpoint is a simple bubble. Bubbles go all the way to the top of the runtime and are handled by the parent. Complex bubbles work entirely differently, and although they are also bubbles, they can be handled by different parts of the program.
A breakpoint is added to YASS code by writing #breakpoint# where the code should break. In the GUI mode, it will display a variable watch window:
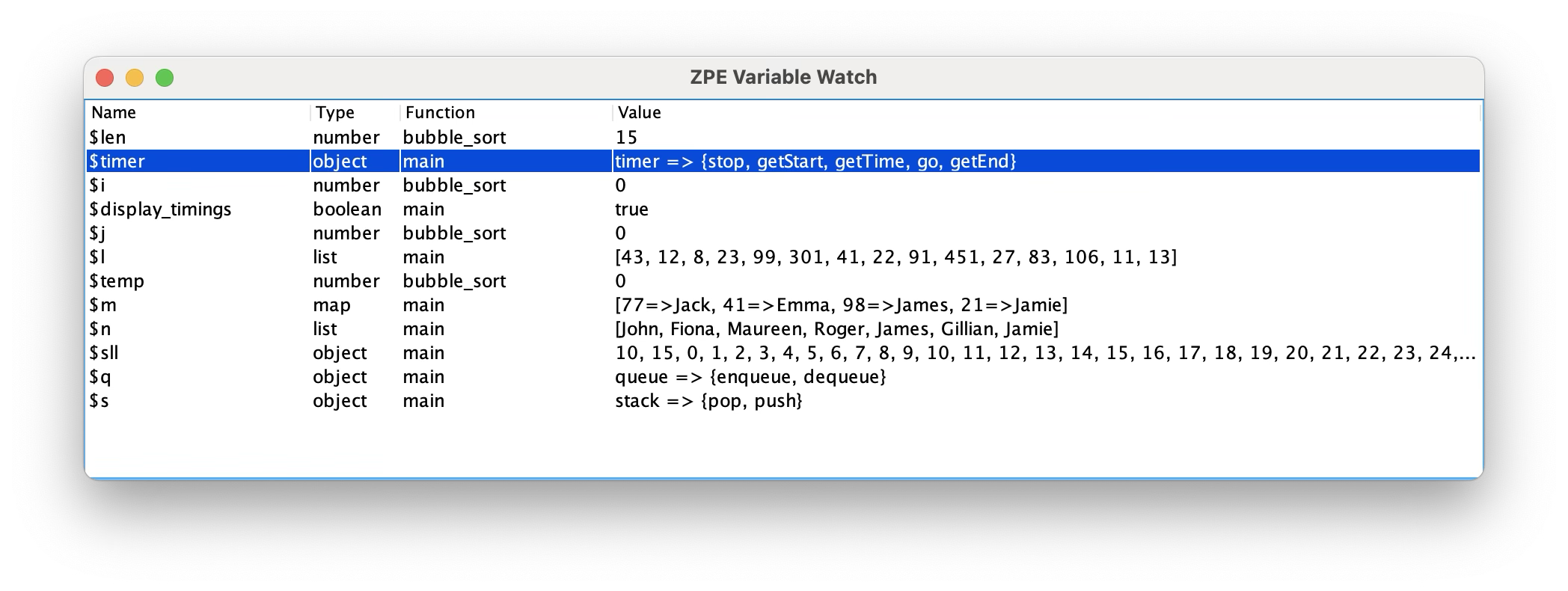
Another prominent feature brought to ZPE this year is bubbling. ZPE will introduce bubbling with version 1.12.7. It is used for interrupts such as exit requests, errors, and breakpoints. These are called bubbles since they are up to the program's top. So, for example, an exit request no longer exits ZPE; it handles a bubble instead to decide what to do with it (and, of course, that might be to exit, or it might be to close the active thread).
Bubbling is a huge feature that changes many of the underlying implementations of ZPE.
I have just made one of the most difficult decisions in my life.
Three weeks ago or so, I saw a post at Edinburgh Academy. I had always liked Edinburgh Academy (and as you may know, I also do one of their websites), and I was in a difficult position at work, which added to my decision to apply. And so I did, and I completed my application a couple of days ago.
I went for the interview, which I think went well. I taught a lesson before, and it went very well. I spent a lot of time preparing the lesson materials but did what I usually do and just naturally taught. In the actual interview, I was open and honest and felt right at home talking to the panel. I could see myself working here.
I was offered the job but needed to think about it.
Unfortunately, the journey was very difficult - and I only learned this on the day. Each way, it took around 1 hour and 30 minutes to travel. Compared to the five minutes down the road that I have at present, this was something I knew my body could not go back to (I remember doing this when I worked on the west side of Edinburgh back in 2017).
So, ultimately, my heart was set on the job, but my brain was telling me no.
I decided to decline the offer with great sadness. To me, this was not a choice—it was the only way this could go.
However, I still love Knox, and for that reason, it doesn't feel as bad a knock. I'm still glad I applied (and was offered the job).
One of the significant updates coming to ZPE 1.12.7 is a major change to how ZPE handles library imports. This post is designed to outline this change so I can reference it from the changelog and GitHub commit.
Before this version, ZPE would read in library imports from a yex file in the libraries folder. This hasn't changed. The library files themselves need not be recompiled. However, the way they are imported has changed. In the older version of ZPE, a library was imported as a variable with all the structures and classes being defined within them:
import stdLib
print($stdLib->bubble_sort([2, 7, 1, 6]))
In ZPE 1.12.7, this changes. Now, instead of adding the bubble_sort function to the $stdLib object, the bubble_sort is put into the top level of the runtime (i.e. added to the global function), so instead you would call bubble_sort:
import stdLib
print(bubble_sort([2, 7, 1, 6]))
ZPE 1.12.7 also allows doing this in the old manner by using the new import as syntax:
import stdLib as stdLib
lib = new stdLib()
print(lib->bubble_sort([2, 7, 1, 6]))
This new change will make some difference to the way in which libraries are used and will improve ZPE performance and memory footprints.
